Principes généraux
Principes généraux
# Onboarding et modèle de données Skalin
# Connecter vos outils
La première étape de votre onboarding consiste à connecter les solutions que vous utilisez déjà dans votre entreprise : CRM, messagerie, outil de facturation, etc. Skalin intègre différents types de données, notamment :
- CLIENTS : vos clients et certaines propriétés qui leur sont associées.
- CONTACTS : vos contacts et certaines propriétés qui leur sont associées.
- CONTRATS : informations sur les contrats avec vos clients (MRR, date de début, date de fin, etc.).
- INTERACTIONS : emails, tickets, rendez-vous, conversations téléphoniques avec vos clients.
- ACTIVITES : détails des connexions à votre produit.
# Modèle de données
Le modèle de données B2B de Skalin est centré sur le CLIENT :
- Vous ne pouvez pas créer un CONTACT sans avoir préalablement créé le CLIENT correspondant.
- Les INTERACTIONS et ACTIVITES sont liées aux CONTACTS : sans CONTACT, ces données ne seront pas prises en compte par Skalin.
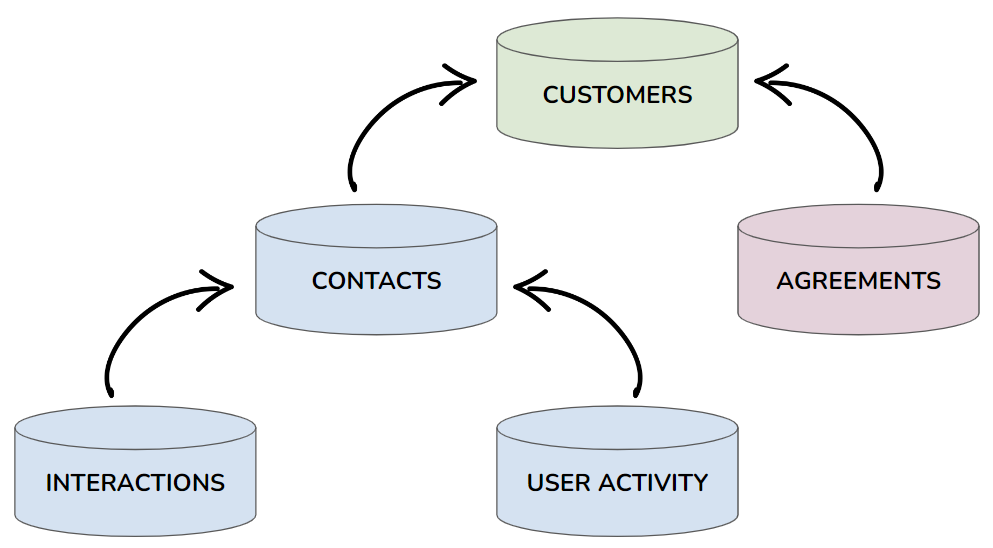
Configuration recommandée :
- Intégrer les CLIENTS puis les CONTACTS.
- Connecter vos comptes de messagerie/ticketing pour centraliser les INTERACTIONS, puis configurer le tracking des ACTIVITES.
Astuce
Vous pouvez connecter le tracking des ACTIVITES en avance, mais Skalin ne récupérera les données qu'à partir du moment où les contacts associés auront été importés.
# Cohérence des IDs
Autre principe important, celui de cohérence des IDs. Un des principes de la plateforme est de centraliser des données présentes sur différents systèmes (CRM, outil de facturation, etc.). Il faut donc que l'on ait une information nous permettant de "reconnaître" un CUSTOMER ou un CONTACT sur les différentes sources.
Deux exemple :
- Si vous avez un CUSTOMER X présent dans votre CRM HubSpot, dans votre outil de facturation STRIPE et sur votre système interne, comment identifier qu'il s'agit du même client ? Avec une clé commune. Cette clé peut-être un identifiant interne présent sur tous vos outils - mais c'est assez rare que ce soit fait ! A défaut, il peut s'agir par exemple du nom de domaine, voire dans certains cas de l'intitulé du compte.
- Même chose pour un CONTACT Y : s'il possède un ID HubSpot d'un côté et un ID interne de l'autre, le matching ne fonctionnera pas. Il faudra dans ce cas utiliser une clé telle que l'email.
Généralement, vous aurez une source de données principale (par exemple votre CRM), autour de laquelle vont graviter des sources de données secondaires. Non pas qu'elles ne soient pas importantes, mais parce qu'elles vont dépendre de la première source.
Imaginons que vos clients et vos contacts soient importés depuis HubSpot, et que vous souhaitez récupérer les informations des contrats via Stripe : dans ce cas, les informations de Stripe viendront enrichir les données de votre CRM HubSpot. Et il faudra qu'une information dans Stripe permette à Skalin de savoir qu'il s'agit du même client dans Stripe que dans HubSpot (cf. Cohérence des IDs (opens new window)).
Attention
Veillez à n'utiliser qu'une seule source par type de donnée afin d'éviter tout conflit ou risque de doublon.
Maintenant que vous êtes au clair sur ces principes fondamentaux, voyons comment connecter vos outils !